We provide a toy graph visualized as follows:
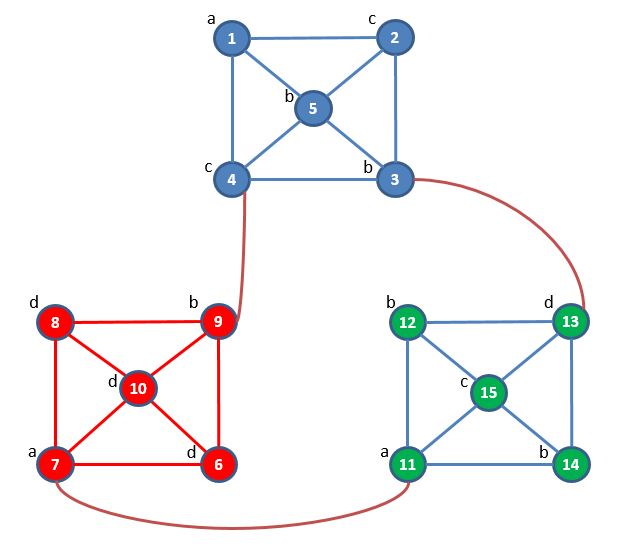
We provide two versions of this toy graph, an unlabeled one and a labeled one. The unlabeled graph is the input to our applications triangle counting and maximum clique finding, while the labeled graph is the input to our subgraph matching application program.
Graph Format
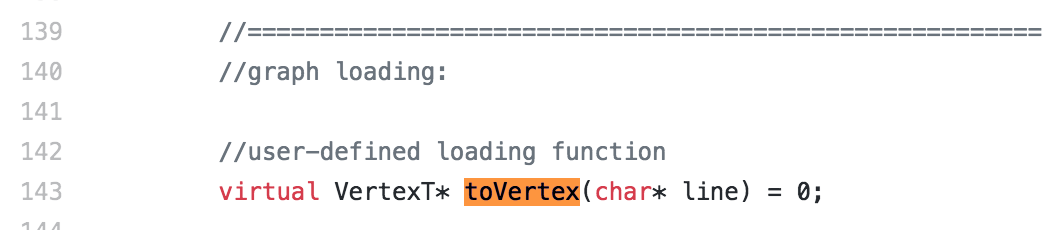
Users may specify how to parse a line into a Vertex object during graph loading, using G-thinker's Worker class, user-defined function toVertex:
By default, our triangle counting and maximum clique finding applications take an input data where each line has the format:
vertex-ID \t number-of-neighbors neighbor1-ID neighbor2-ID neighbor3-ID ...
By default, our subgraph matching application takes an input data where each line has the format:
vertex-ID label \t neighbor1-ID neighbor1-label neighbor2-ID neighbor2-label neighbor3-ID neighbor3-label ...
We provide tools for you to conveniently process your big data in parallel into the above formats. This program allows you to convert an input graph where each line is an edge into a graph with adjacency list format, where a detailed ReadMe file is provided about how to run it.
You may generate a randomly-labeled graph from an unlabeled graph using this program or its memory-efficient version. For each one, a detailed README file is provided about how to run it. It uses the attribute broadcast algorithm described in Section 3.1 of this paper to attach labels with every item in adjacency lists, and you may easily change our code's vertex parsing UDF to take a provided label.
Upload Graphs to HDFS
G-thinker requires that a large graph data is partitioned into smaller files under the same data folder on HDFS, and these files are loaded by different computing processes during processing.
To achieve this goal, we cannot simply use the command hadoop fs -put {local-file} {HDFS-path}. Otherwise, all the data file will be loaded by only one computing process, and the other processes simply wait for it to finish loading.
To put a large graph data onto HDFS, one needs to compile and run this data-putting program with two arguments being {local-file} {HDFS-path}.